Deep dive on load balanced ECS Service deployments with CloudFormation
by Philipp Garbe
Being able to continuously deploy your application is an important part of your success. For ECS based applications there are not only multiple ways to deploy but also several options like container health checks, grace periods, container dependencies, and ALB health checks to adjust the behavior.
The goal of this blog post is to show what exactly happens during the deployment to get a better understanding of how these settings work together.
For the matter of simplification this blog post focuses on an ECS Service running on Fargate behind an Application LoadBalancer. It uses the built-in rolling update deployment type for CloudFormation. Other use-cases and configurations might differ a bit.
Involved components
First, an overview of all components and settings that are involved:
ECS Task
A task is a logical construct for executing one or more containers. Tasks have their own lifecycle to indicate the current state of the containers and it can change from PENDING to ACTIVATING, RUNNING, DEACTIVATING, STOPPING, DEPROVISIONING and finally STOPPED.
If a task contains several containers, it is important to consider their relationship to each other. This dependency is especially important during starting and stopping. It can vary from Start (the other container must be started before), Complete (the other container must be started and finished), Success (the other container must be started and finished successfully) or Healthy (the other container must be started and its health checks must be green).
Each container of a task can define its own health check. These parameters correspond to the HEALTHCHECK parameters of docker run. Note that the HEALTHCHECK within a docker file is not considered by ECS. A typical health check contains a command that is executed and must be successful multiple times (retries). The time between these calls is called interval. The interesting part here is startPeriod. It’s an optional grace period to provide containers time to bootstrap before failed health checks count towards the maximum number of retries.
ECS Service
The ECS Service is responsible to start and stop tasks and to (de)register them with the LoadBalancer. It also orchestrates deployments of newer versions.
The optional deploymentConfiguration parameters controls how many tasks run during the deployment. It’s only used with ECS rolling update deployment type (blue/green (CODE_DEPLOY) or EXTERNAL deployment types ignore these settings). minimumHealthyPercent indicates the percentage of tasks that must remain in RUNNING status during a deployment, depending on the desiredCount. maximumPercent parameter represents an upper limit on the number of your service’s tasks that are allowed in the RUNNING or PENDING state during a deployment. It’s always a percentage of the current desiredCount.
Application Load Balancer
As soon as a task has reached the RUNNING state, it is added as a target to the configured TargetGroups of the LoadBalancer. The TargetGroup must define a health check which controls the status of the target. Similar to container health check there are a command, interval and retries. The target starts as initial and can then switch to either healthy or unhealthy. As soon as it is healthy it gets traffic. If a target becomes unhealthy the ECS service takes care to stop the task and start a new one if necessary.
To support tasks that need longer to start a healthCheckGracePeriod can be defined. This period starts as soon as the container changes to RUNNING status and during this time health checks of the LoadBalancer TargetGroups as well as container and Route 53 health checks are ignored.
CloudFormation
ECS TaskDefinitions and Service Definitions can be defined as resources in a CloudFormation template. When the CloudFormation stack is created, not only the defined resources are created but CloudFormation also starts an ECS deployment where the ECS service takes care of starting the required number of tasks. A change of the task definition and a subsequent update of the CloudFormation stack also leads to a new ECS deployment.
The life of an ECS Task
Now that we know all the important components involved, let’s take a closer look at what happens when an ECS task is started.
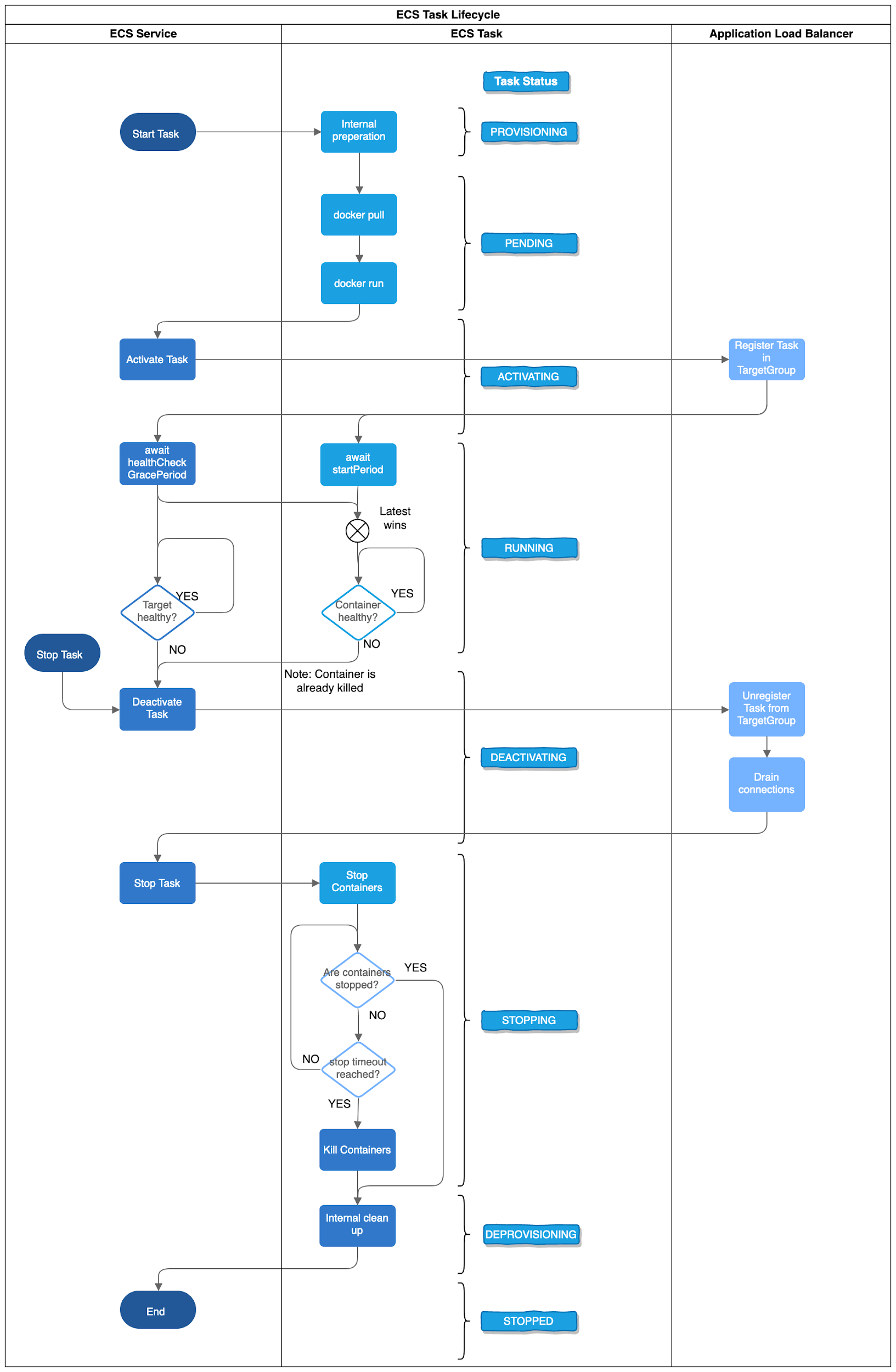
Every task starts with the PROVISIONING status. Thereby internal resources such as network interfaces are provisioned.
Then the task changes to PENDING and the ECS Agent tries to pull the Docker Image from the registry and runs it. As soon as the container is started the configured container health check is executed by the Docker Daemon.
Dependencies between the configured containers are also considered in this phase. For example, if there is a dependency from Container App to Container Sidecar with condition healthy, Container Sidecar will be started first. And only if this container is healthy the App Container is started.
Once the task has been successfully started, it gets the ACTIVATING status and is registered with all configured TargetGroups. Also, the respective health checks are started.
After the successful registration of the task it changes to the RUNNING status. It keeps this status until either the process in the container ends, the container health check or the LoadBalancer health check fails or the task is terminated by the ECS service.
If a startPeriod is defined for the container HealthCheck, the results of the health check for this period are ignored. In case the healthCheckGracePeriod is also configured, the larger value wins. If the health check is unhealthy the Docker Daemon stops this container and the ECS task is stopped (if the task is marked as essential which is the default).
Similarly, if the TargetGroup has the healthCheckGracePeriod defined, the results of the LoadBalancer health checks are ignored during this period. Task which are healthy gets traffic from the load balancer but once they become unhealthy no more traffic is sent to them and the ECS service takes care that the Task gets stopped.
With DEACTIVATING the task is unregistered at all configured TargetGroups. For the duration of the configured deregistration_delay timeout, the load balancer will allow existing requests made to complete. Once the timeout is reached, any remaining connections will be forcibly closed.
Afterwards in the STOPPING phase, ECS tries to stop the running containers of the task gracefully (sending SIGTERM). If the container is already stopped because the container health check failed, this step is skipped. Otherwise, the system waits until the configured stopTimeout of the container is reached and forcefully kills the container (SIGKILL). If no stopTimeout is set, a default of 30 seconds is used.
The resources created in the provisioning phase will be cleaned up again during DEPROVISIONING. And finally, the task reaches its final STOPPED status.
Rolling Update Deployments with CloudFormation
CloudFormation is one of multiple ways to run an ECS deployment. Thereby a Rolling Update is performed which can be adjusted with the deploymentConfiguration.
Unfortunately, the interaction between CloudFormation, ECS and the ALB can lead to unexpected results. The table shows which combinations lead to which final stack status. The lines with ❗ should indicate which results are not necessarily expected.
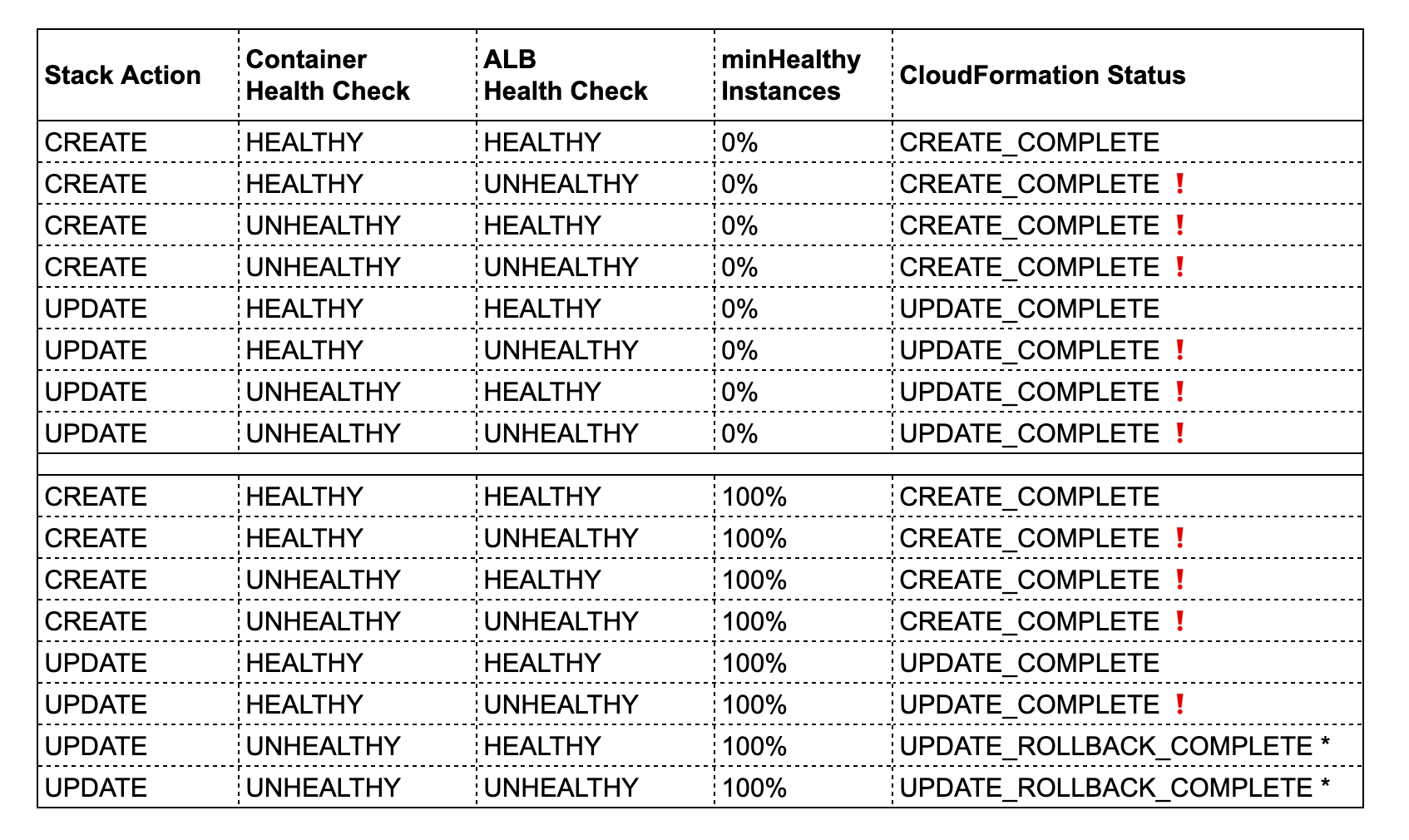
* The rollback is triggered after a timeout of 3 hours where CloudFormation waits for the ECS Service deployment to stabilize.
Unexpectedly, if an UPDATE fails, not only the current ECS deployment is aborted, but another ECS deployment with the previous (old) configuration is started. This means that even with a rollback in CloudFormation, another ECS deployment will take place, which can potentially compromise the availability of the service.
Learnings and Recommendations
This is a list of things that are not obvious but very important to keep in mind:
-
Failed container health checks (at any time) stops the container immediately which leads to deregistering on the ALB afterwards (connections will probably be dropped as the task already stopped). Failed ALB health checks trigger ECS to wait until connections are drained and then stop the task (“Deactivating” phase).
-
Task gets registered at ALB immediately in RUNNING status without waiting for the result of container health checks. In case the container health check takes longer than the ALB health check the task actually gets traffic in the meantime which is then interrupted when the container health check fails.
-
CloudFormation rollback means that it triggers a new ECS deployment with the former taskdefinition (which could lead to some troubles as well)
-
A CloudFormation stack creation will always complete successfully even with failing health checks and independent of any deploymentConfiguration
-
A CloudFormation stack update will fail only if minimumHealthyPercent is 100%, and the container health check is unhealthy. And it takes CloudFormation 3 hours before it triggers the rollback.
-
healthCheckGracePeriods is considered on all health checks (container, load balancer and route53). It kind of overwrites startPeriod which is only for container health checks.
What should you do now?
-
Have both kinds of health checks (container and load balancer) configured.
-
If you use CloudFormation monitor your deployments and roll them back by yourself
-
Try to use blue/green deployment with CodeDeploy instead of Rolling Update (The roadmap says CloudFormation support is coming soon)
Subscribe via RSS
{kind=link}