A better solution to ECS AutoScaling
by Philipp Garbe
Update:
It seems this blog post was the trigger for AWS to build their own solution. Since CapacityProviders are released I recommend to use them instead. Have a look into Nick Coulton’s deep dive to understand how they work.
In a previous blog post, I showed you how an ECS cluster can automatically scale by using the built-in CloudWatch metrics. While this works very well when you scale out, it is still an issue to scale in because you’ve to choose one of the two metrics (CPU or memory). This article explains how a single metric allows you to effectively scale your cluster up and(!) down.
Instead of scale up and down, I’m now using scale in and out as I think it describes it better, because it’s about horizontal scaling.
The problem of scaling in
A limitation of CloudWatch alarm is that it allows you to choose only one metric at a time. It’s possible to set up two different alarms (one for CPU and one for memory) and trigger the AutoScaling Group to scale out. But when both metrics are used to scale in, you run into troubles. Imagine when you have high CPU but low memory reservation. One alarm tries to scale out while the other wants to scale in. You end up in a situation where a new container instance is launched and another terminated again and again.
This gets even worse because tasks are not re-scheduled when a new container instance gets launched. But when AutoScaling group terminates an instance, it normally chooses the oldest one (usually with many tasks running). That makes the cluster unstable as the tasks need to be scheduled over and over again.
It’s impossible to scale in and out with two different metrics.
One metric to scale them all
When two metrics are problematic, the solution must be one metric, right? Ideally, a new metric, as the default metrics (CPU or memory reservation) can’t be used. Also, it should be easy to setup when the cluster should scale in and out.
The constraint is still, that it should be possible to start the largest container.
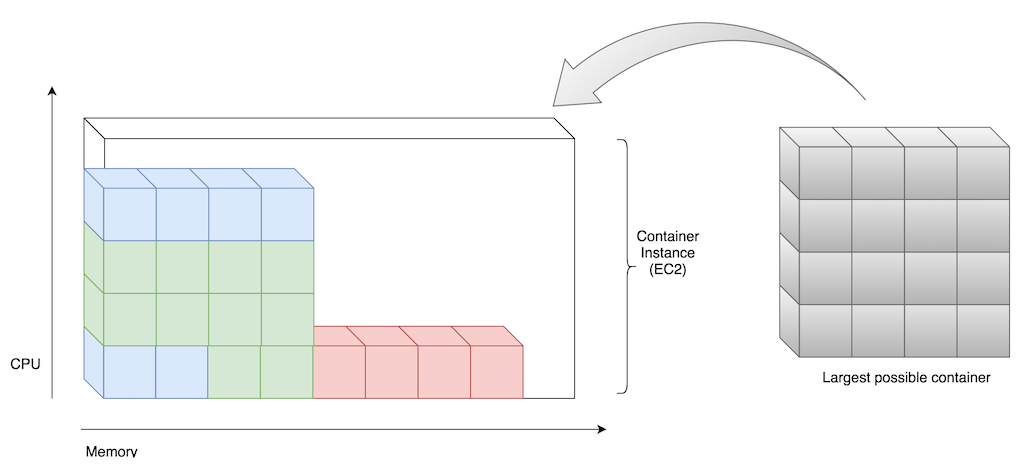 Keep enough resources to schedule the largest container
Keep enough resources to schedule the largest container
The solution is a metric which shows the number of largest containers that could be scheduled. It’s calculated based on CPU and memory.
A cron-based lambda can be used to calculate this number. First, the available CPU is used to calculate how many of the largest containers can be scheduled. Second, the same happens for memory. The lowest number of this two calculations wins and at the end, it will be summed up for all container instances. Finally, this number gets written to CloudWatch.
CONTAINER_MAX_CPU = 1024
CONTAINER_MAX_MEM = 4096
def lambda_handler(event, context):
cluster = os.environ.get('ECS_CLUSTER')
print('Calculating schedulable containers for cluster %s' % cluster)
instance_list = ecs.list_container_instances(cluster=cluster, status='ACTIVE')
instances = ecs.describe_container_instances(cluster=cluster,
containerInstances=instance_list['containerInstanceArns'])
schedulable_containers = 0
for instance in instances['containerInstances']:
remaining_resources = {resource['name']: resource for resource in instance['remainingResources']}
containers_by_cpu = int(remaining_resources['CPU']['integerValue'] / CONTAINER_MAX_CPU)
containers_by_mem = int(remaining_resources['MEMORY']['integerValue'] / CONTAINER_MAX_MEM)
schedulable_containers += min(containers_by_cpu, containers_by_mem)
print('%s containers could be scheduled on %s based on CPU only' % (containers_by_cpu, instance['ec2InstanceId']))
print('%s containers could be scheduled on %s based on memory only' % (containers_by_mem, instance['ec2InstanceId']))
print('Schedulable containers: %s' % schedulable_containers)
cw.put_metric_data(Namespace='AWS/ECS',
MetricData=[{
'MetricName': 'SchedulableContainers',
'Dimensions': [{
'Name': 'ClusterName',
'Value': cluster
}],
'Timestamp': datetime.datetime.now(dateutil.tz.tzlocal()),
'Value': schedulable_containers
}])
print('Metric was send to CloudWatch')
return {}
(Code provided by Johannes Müller)
Example:
As an example, let’s say the largest container needs 4096mb and 1024 CPU Cores (~ 1 vCPU). The ECS cluster has 3x m4.2xlarge instances (32.0 GB / 8 vCPUs).
| Containern Instance | Available CPU | Available Memory | # of largest containers possible |
|---|---|---|---|
| 1 | 6.5 vCPUs | 28 GB | 6 |
| 2 | 0.5 vCPUs | 3 GB | 0 |
| 3 | 4 vCPUs | 6 GB | 1 |
Container instance #1 can schedule 6 of the largest containers. The available CPU is enough for 6 and the memory is enough for even 7 container tasks. In that case, the lower number wins. Container instance #2 is easy, as there are not enough resources. And on container instance #3 only one task could be scheduled as there is not so much memory available.
In total, the cluster can schedule 7 additional tasks and it should scale in to save some money.
This is very effective in combination with BinPack strategy. The ECS scheduler tries to fill the first node as much as possible before tasks are scheduled on another node. As long as the largest container can be scheduled, AutoScaling Group does not need to scale out.
Automatic and Effective Scaling
The definition of the CloudWatch alarms is easy. One alarm triggers the AutoScaling Group to scale out and another alarm tells the AutoScaling Group to scale in.
SchedulableContainersLowAlert:
Type: AWS::CloudWatch::Alarm
Properties:
EvaluationPeriods: '1'
Statistic: Minimum
Threshold: '1'
AlarmDescription: Alarm if less than 1 containers with maximum size can be scheduled
Period: '60'
AlarmActions:
- Ref: ClusterScaleOutPolicy
Namespace: AWS/ECS
Dimensions:
- Name: ClusterName
Value: !Ref ECSCluster
ComparisonOperator: LessThanThreshold
MetricName: SchedulableContainers
SchedulableContainersHighAlert:
Type: AWS::CloudWatch::Alarm
Properties:
EvaluationPeriods: '1'
Statistic: Minimum
Threshold: '8'
AlarmDescription: Alarm if more than 8 containers with maximum size can be scheduled
Period: '60'
AlarmActions:
- Ref: ClusterScaleInPolicy
Namespace: AWS/ECS
Dimensions:
- Name: ClusterName
Value: !Ref ECSCluster
ComparisonOperator: GreaterThanThreshold
MetricName: SchedulableContainers
The setup in CloudFormation
More interesting is which values have to be set as Threshold.
To scale out, the threshold of the SchedulableContainersLowAlert should be 1 to make sure that at least one instance of the largest possible container can be scheduled. Greater thresholds can make sense when it’s likely that multiple of the largest containers are started at the same time.
To scale in, the threshold of the SchedulableContainersHighAlert needs to be calculated. It has to be greater than the number of maximum containers that can be placed on one container instance.
Threshold = min ( cpu(ec2) / cpu (container), memory(ec2) / memory (container))
In our example the container instance is a m4.2xlarge instances (32.0 GB / 8 vCPUs):
Threshold = min ((8192 / 1024), (32,768 / 4096))
Threshold = min (8, 8)
Threshold = 8
Because 8 containers can be placed on one container instance, the threshold when the cluster should scale in needs to be greater than 8. Otherwise, it starts a loop of scaling out and in.
One solution of many
This solution is just one of many attempts how you can automatically and effectively scale an ECS cluster in and out. I’m very interested in your feedback and how you solve the scaling problem.
Subscribe via RSS
{kind=link}