Docker on ECS: Scale your cluster automatically
by Philipp Garbe
When you run an ECS cluster in production it happens that the cluster becomes too small and it can’t schedule new tasks (AWS term for running containers). Of course, you can add new container instances (EC2) but why should you do it manually when you can automate it? On the other side can you also scale down automatically to save money?
“If you do it twice, automate it.”
(source: unknown)
AutoScaling Group
EC2 instances can be grouped inside an AutoScaling Group which adds or removes instances automatically based on CloudWatch metrics. This also applies to container instances of ECS. Container instances are basically EC2 machines with Docker and ECS-Agent installed.
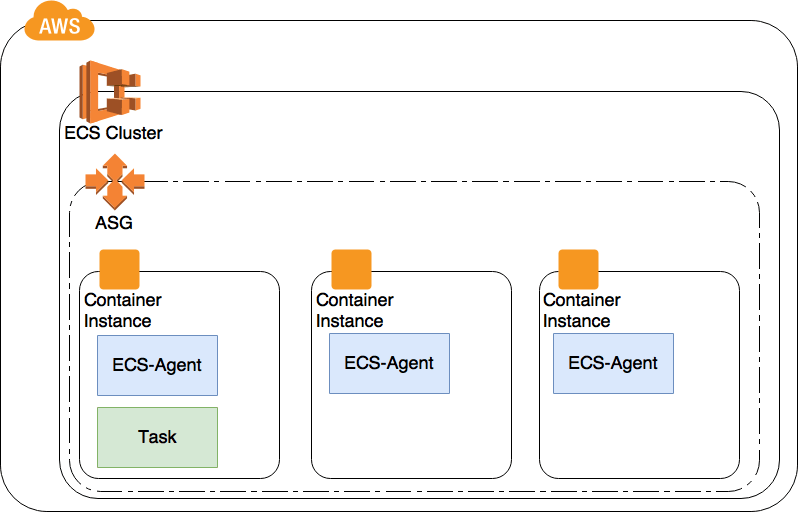 ECS cluster and AutoScaling Group
ECS cluster and AutoScaling Group
If you want to use your own AMI you not only have to install Docker and the ECS-Agent but also tweak the iptables in order to get TaskRoles running. See here for detailed instructions.
CloudWatch metrics
In order to trigger the AutoScaling group to change the desired count you’ve to create a scaling policy that uses CloudWatch alarms.
AWS provides four CloudWatch metrics for your cluster:
- CPU Utilization
- Memory Utilization
- CPU Reservation
- Memory Reservation
The CPU/Memory utilization tells you how much of your hardware is actually used. The CPU/Memory reservation metrics are based on the settings that you’ve defined in your task definition. For auto scaling the utilization metrics are not useful because ECS starts new tasks only when there is enough capacity based on reserved CPU or memory.
To demonstrate the behavior assume we have only one container instance with 4 CPU cores and 4096 MB memory. The task we want to start needs 1500 CPU units (1024 CPU Units = 1 Core) and 768 MB memory.
| # of Tasks | CPU Reservation | Memory Reservation | State |
|---|---|---|---|
| 1 | ~36% (1500 Cores) | 18,75% (768 MB) | Started |
| 2 | ~72% (3000 Cores) | 37,50% (1536 MB) | Started |
| 3 | 108% !! | 56,25% (2304 MB) | Failed |
The 3rd instance of our task can’t be scheduled because there is already 72% of the available CPU units reserved and it the task would need another 36%. It doesn’t matter if your task actually needs the CPU or memory. Maybe your cluster idles but ECS would not start another task.
Only reserved capacity is considered by the ECS scheduler.
Scaling up
Scaling up means adding new container instances to the cluster in order to provide more capacity. In this case, both reservation metrics can be used. The ECS cluster can be increased when either reserved CPU is, for example, greater 80% or the reserved memory is greater 80%. The configuration itself is straightforward.
CPUReservationScaleUpPolicy:
Type: AWS::AutoScaling::ScalingPolicy
Properties:
AdjustmentType: ChangeInCapacity
AutoScalingGroupName: !Ref: ECSAutoScalingGroup
Cooldown: '300'
ScalingAdjustment: '1'
CPUReservationHighAlert:
Type: AWS::CloudWatch::Alarm
Properties:
EvaluationPeriods: '1'
Statistic: Maximum
Threshold: '80'
Period: '60'
AlarmActions:
- !Ref: CPUReservationScaleUpPolicy
Dimensions:
- Name: ClusterName
Value: !Ref: ECSCluster
ComparisonOperator: GreaterThanThreshold
MetricName: CPUReservation
Namespace: AWS/ECSAlarm definition in CloudFormation
When is the best moment to scale up? Which limits should be used? This depends heavily on the size of your cluster.
Example 1
The setup of our first example consists of 3 running container instances. Each instance has 2048 MB memory so we have in total 6144 MB memory available. Our task now wants to reserve 3096 MB.
| # of Tasks | # of Container Instances | Reserved Memory before | Memory needed | Reserved Memory after | What happens |
|---|---|---|---|---|---|
| 0x | 3x | 0% (0 MB) | 3096 MB | Task can’t be scheduled |
The AutoScaling Group will not be triggered. Even if it would be triggered, it had no effect. The task can’t be scheduled on any of the container instances as no one fulfills the requirement of 3096 MB of memory.
Be aware what’s your maximum of memory and CPU of a single container instance. Tasks can not reserve more than that.
Example 2
Let’s change our setup. In this example, we have an ECS cluster starting with one container instance which has 2048 MB Memory. Our task needs 512 MB memory. We want to scale up when the reserved memory capacity is greater than 70%.
| # of Tasks | # of Container Instances | Reserved Memory before | Memory needed | Reserved Memory after | What happens |
|---|---|---|---|---|---|
| 0 | 1 | 0% (0 MB) | 512 MB | 25% (512 MB) | Task is scheduled |
| 1 | 1 | 25% (512 MB) | 512 MB | 50% (1024 MB) | Task is scheduled |
| 2 | 1 | 50% (1024 MB) | 512 MB | 75% (1536 MB) | Task is scheduled. ASG is scaling up |
| 3 | 2 | 37,5% (1536 MB) | 512 MB | 50% (2048 MB) | Task is scheduled |
Now the AutoScaling group gets triggered and starts another container instance.
Example 3
In order to have a better utilization of our cluster lets change our scaling policy to 80% and see what happens.
| # of Tasks | # of Container Instances | Reserved Memory before | Memory needed | Reserved Memory after | What happens |
|---|---|---|---|---|---|
| 0 | 1 | 0% (0 MB) | 512 MB | 25% (512 MB) | Task is scheduled |
| 1 | 1 | 25% (512 MB) | 512 MB | 50% (1024 MB) | Task is scheduled |
| 2 | 1 | 50% (1024 MB) | 512 MB | 75% (1536 MB) | Task is scheduled |
| 3 | 1 | 75% (1536 MB) | 512 MB | Task can’t be scheduled |
When ECS tries to start a task it checks if the cluster has enough capacity to handle the task. In this example, there is not enough capacity to start the 4th task. Unfortunately, the reserved CPU/memory metrics return only the current state and they do not include the reserved CPU/memory of the task we want to start. Therefore the metrics are still unchanged and the AutoScaling Group doesn’t get triggered.
Example 4
Maybe you say one instance is not a real example. What about 100 instances? Each of the instances has again 2048 MB memory and we want to scale up when the reserved memory capacity is greater than 80%. Let’s see how many tasks can be started 100 * 2048mb = 204,800mb
| # of Tasks | # of Container Instances | Reserved Memory before | Memory needed | Reserved Memory after | What happens |
|---|---|---|---|---|---|
| 0 | 100 | 0% (0mb) | 512 MB | 0,25% (512mb) | Task is scheduled |
| 1 | 100 | 0,25% (512mb) | 512 MB | 0,50% (1024mb) | Task is scheduled |
| 30 | 100 | 0,50% (1024mb) | 512 MB | 7,50% (15,360mb) | Task is scheduled |
| 90 | 100 | 7,50% (15,360mb) | 512 MB | 22,50% (46,080mb) | Task is scheduled |
| 150 | 100 | 22,50% (46,080mb) | 512 MB | 37,50% (76,800mb) | Task is scheduled |
| 300 | 100 | 37,50% (76,800mb) | 512 MB | 75,00% (153,600mb) | Task is scheduled |
| 301 | 100 | 75,00% (153,600mb) | 512 MB | 75,00% (153,600mb) | Task can’t be scheduled |
Again our cluster does not automatically scale. Like in example 3 the task can’t be scheduled because no single container instance can provide the needed capacity.
I know that these examples are theoretical because normally you don’t have such an even distribution. My intention is to bring awareness which metrics needs to be considered and how to interpret them.
Rule of thumb
In the end, the size of your cluster is not important for your AutoScaling policies. Important is the maximum memory or CPU of any of your tasks (containers) and the capacity of one of your container instances (basically the ec2 instance type). Based on that you can calculate the percentage when you have to scale your cluster.
Threshold = (1 - max(Container Reservation) / Total Capacity of a Single Container Instance) * 100
Now we can calculate the threshold for the examples above:
Container instance capacity: 2048 MB
Maximum of container reservation: 512 MB
Threshold = (1 - 512 / 2048) * 100 Threshold = 75%
We calculated the threshold now only for memory but normally would need to do that for CPU as well. And the lower number of these two thresholds should be used.
What’s next?
My origin plan was to write about upscaling and downscaling. But I did not expect that upscaling is such a big topic and therefore I decided to split it up and write another blog post about downscaling.
You maybe asked yourself also what happens to my running tasks when the cluster scales up and down? I consciously avoided ‘scheduling’ in this blog post because it’s a topic by its own.
If you want to try it out by yourself have a look on my GitHub repository which contains the example code.
I love feedback, so let me know what you think.
Subscribe via RSS
{kind=link}